Общие определения
Целью дисперсионного анализа (ANOVA – Analysis of Variation) является проверка значимости различия между средними в разных группах с помощью сравнения дисперсий этих групп. Разделение общей дисперсии на несколько источников (связанных с различными эффектами в плане), позволяет сравнить дисперсию, вызванную различием между группами, с дисперсией, вызванной внутригрупповой изменчивостью.
Проверяемая гипотеза состоит в том, что различия между группами нет. При истинности нулевой гипотезы, оценка дисперсии, связанной с внутригрупповой изменчивостью, должна быть близкой к оценке межгрупповой дисперсии. При ложности - значимо отклоняться.
В целом дисперсионный анализ может быть разделён на несколько видов:
одномерный (одна зависимая переменная) и многомерный (несколько зависимых переменных);
однофакторный (одна группирующая переменная) и многофакторный (несколько группирующих переменных) с возможным взаимодействием между факторами;
с простыми измерениями (зависимая переменная измеряется лишь один раз) и с повторными (зависимая переменная измеряется несколько раз).
В STATISITICA реализованы все известные модели дисперсионного анализа.
В STATISITICA дисперсионный анализ можно провести с помощью модуля Дисперсионный анализ в блоке STATISITICA Base (Анализ -> Дисперсионный анализ(ДА)) . Для построения модели специального вида используется полная версия Дисперсионного анализа, представленная в модулях Общие линейные модели , Обобщённые линейные и нелинейные модели , Общие регрессионные модели , Общие модели частных наименьших квадратов из блока Углубленные методы анализа (STATISTICA Advanced Linear/Non-Linear Models ).
в начало
Пошаговый пример в STATISTICA
Мы будем иллюстрировать возможности дисперсионного анализа в STATISITICA , рассматривая пошаговый модельный пример.
Исходный файл данных описывает совокупность людей с разным уровнем дохода, образования, возраста и пола. Рассмотрим, как влияют уровень образования, возраст и пол на уровень дохода.
По возрасту все люди были разделены на четыре группы:
до 30 лет;
от 31 до 40 лет;
от 41 до 50 лет;
от 51 года.
По уровню образования произошло деление на 5 групп:
незаконченное среднее;
среднее;
среднее профессиональное;
незаконченное высшее;
высшее.
Так как данные модельные, то полученные результаты будут носить в основном качественный характер и иллюстрировать способ проведения анализа.
Шаг 1. Выбор анализа
Выберем дисперсионный анализ из меню: Анализ -> Углубленные методы анализа -> Общие линейные модели .
Рис. 1. Выбор дисперсионного анализа из выпадающего меню STATISTICA
Далее откроется окно, в котором представлены различные виды анализа. Выбираем Вид анализа – Факторный Дисперсионный анализ .

Рис. 2. Выбор вида анализа
В этом окне также можете выбрать способ построения модели: диалоговый режим или использовать мастер анализа. Выберем диалоговый режим.
Шаг 2. Задание переменных
Из открытого файла данных выберем переменные для анализа, щелкните кнопку Переменные , выберете:
Доход – зависимая переменная,
Уровень образования , Пол и Возраст – категориальные факторы (предикторы).
Заметим, что Коды факторов в этом простом примере можно не задавать. При нажатии на кнопку OK , STATISTICA задаст их автоматически.

Рис. 3. Задание переменных
Шаг 3. Изменение опций
Обратимся к вкладке Опции в окне GLM Факторный ДА .

Рис. 4. Вкладка Опции
В этом диалоговом окне вы можете:
выбрать случайные факторы;
задать тип параметризации модели;
указать тип сумм квадратов (SS), имеется 6 различных сумм квадратов (SS);
включить проведение кросс-проверки.
Оставим все установки по умолчанию (этого достаточно в большинстве случаев) и нажмём кнопку ОК .
Шаг 4. Анализ результатов – просмотр всех эффектов
Результаты анализа можно посмотреть в окне Результаты с помощью вкладок и группы кнопок. Рассмотрим, например, вкладку Итоги .

Рис. 5. Окно анализа результатов: вкладка Итоги
С этой вкладки можно получить доступ ко всем основным результатам. Воспользуйтесь остальными вкладками для получения дополнительных результатов. Кнопка Меньше позволяет изменить диалоговое окно результатов, удалив вкладки, которые, как правило, не используются.
При нажатии кнопки Проверить все эффекты получаем следующую таблицу.

Рис. 6. Таблица всех эффектов
Эта таблица выводит основные результаты анализа: суммы квадратов, степени свободы, значения F-критерия, уровни значимости.
Для удобства исследования значимые эффекты (p<.05) выделены красным цветом. Два главных эффекта (Уровень образования и Возраст ) и некоторые взаимодействия в данном примере являются значимыми (p<.05).
Шаг 5. Анализ результатов – просмотр заданных эффектов
Чтобы посмотреть, каким образом средний уровень дохода различается по категориям, удобнее всего воспользоваться графическими средствами. При нажатии на кнопку Все эффекты/графики появится следующее диалоговое окно.

Рис. 7. Окно Таблица всех эффектов
В окне перечислены все рассматриваемые эффекты. Статистически значимые эффекты помечены *.
Например, выберем эффект Возраст , в группе Отображать укажем Таблицу и нажмём ОК . Появится таблица, в которой для каждого уровня эффекта приведено среднее значение зависимой переменной (Доход) , величина стандартной ошибки и границы доверительных пределов.

Рис. 8. Таблица с описательными статистиками по уровням переменной Возраст
Эту таблицу удобно представить в графическом виде. Для этого выберем График в группе Отображать диалогового окна Таблица всех эффектов и нажмём ОК . Появится соответствующий график.

Рис. 9. График зависимости среднего дохода от возраста
Из графика ясно видно, что между группами людей разного возраста есть разница в уровне дохода. Чем выше возраст, тем больше доход.
Аналогичные операции проведём для взаимодействия нескольких факторов. В диалоговом окне выберем Пол *Возраст и нажмём ОК .

Рис. 10. График зависимости среднего дохода от пола и возраста
Получен неожиданный результат: для опрошенных людей в возрасте до 50 лет уровень дохода растёт с возрастом и не зависит от пола; для опрошенных людей старше 50 лет женщины имеют значимо больший доход, чем мужчины.
Стоит построить полученный график в разрезе уровня образования. Возможно, такая закономерность нарушается в некоторых категориях или, наоборот, носит универсальный характер. Для этого выберем Уровень образования * Пол * Возраст и нажмём ОК .

Рис. 11. График зависимости среднего дохода от пола, возраста, уровня образования
Видим, что полученная зависимость не характерна для среднего и среднего профессионального образования. В остальных случаях она справедлива.
Шаг 6. Анализ результатов – оценка качества модели
Выше в основном использовались графические средства дисперсионного анализа. Рассмотрим некоторые другие полезные результаты, которые можно получить.
Во-первых, интересно посмотреть, какую долю изменчивости объясняют рассматриваемые факторы и их взаимодействия. Для этого во вкладке Итоги нажмём на кнопку Общая R модели . Появится следующая таблица.
Рис. 12. Таблица SS модели и SS остатков
Число в столбце Множеств. R2 – квадрат множественного коэффициента корреляции; оно показывает, какую долю изменчивости объясняет построенная модель. В нашем случае R2 = 0.195, что говорит о невысоком качестве модели. В самом деле, на уровень дохода влияют не только факторы, внесённые в модель.
Шаг 7. Анализ результатов – анализ контрастов
Часто требуется не только установить различие в среднем значении зависимой переменной для разных категорий, но и установить величину различия для заданных категорий. Для этого следует исследовать контрасты.
Выше было показано, что уровень дохода для мужчин и женщин значимо отличается для возраста от 51, в остальных случаях различие не значимо. Выведем разницу в уровне дохода для мужчин и женщин в возрасте выше 51 года и между 40 и 50 годами.
Для этого перейдём во вкладку Контрасты и выставим все значения следующим образом.

Рис. 13. Вкладка Контрасты
При нажатии кнопки Вычислить появится несколько таблиц. Нас интересует таблица с оценками контрастов.

Рис. 14. Таблица Оценки контрастов
Можно сделать следующие выводы:
для мужчин и женщин старше 51 года разница в уровне дохода составляет 48,7 тыс. долл. Разница значима;
для мужчин и женщин в возрасте от 41 до 50 лет разница в уровне дохода составляет 1,73 тыс. долл. Разница не значима.
Аналогично можно задать более сложные контрасты или воспользоваться одним из заранее заданных наборов.
Шаг 8. Дополнительные результаты
Используя остальные вкладки окна результатов можно получить следующие результаты:
средние значения зависимой переменной для выбранного эффекта – вкладка Средние ;
проверка апостериорных критериев (post hoc) – вкладка Апостериорные ;
проверка сделанных для проведения дисперсионного анализа предположений – вкладка Предположения ;
построение профилей отклика/желательности – вкладка Профили ;
анализ остатков – вкладка Остатки ;
вывод матриц, используемых в анализе – вкладка Матрицы ;
-
Statistica 6 q. Подготовка корреляционной матрицы для факторного анализа q. Создание матрицы для факторного анализа q. Факторный анализ q. Выделение факторных нагрузок q. Построение факторной диаграммы
 Подготовка корреляционной матрицы для факторного анализа в программе Statistica Поскольку наши ранги представляют собой порядковые шкалы, то адекватными этому виду шкал будут являться два коэффициента: Спирмена и Кендалла. Будем считать Кендаллом, т. к. он более точный. Вводим наши сырые данные в программу Statistica
Подготовка корреляционной матрицы для факторного анализа в программе Statistica Поскольку наши ранги представляют собой порядковые шкалы, то адекватными этому виду шкал будут являться два коэффициента: Спирмена и Кендалла. Будем считать Кендаллом, т. к. он более точный. Вводим наши сырые данные в программу Statistica



 Мы получили факторную матрицу, рассчитанную коэффициентом Кендалла, т. к. именно он является адекватным для наших данных, которые представляют собой шкалы порядка.
Мы получили факторную матрицу, рассчитанную коэффициентом Кендалла, т. к. именно он является адекватным для наших данных, которые представляют собой шкалы порядка. Создание матрицы для расчета ФА Теперь нужно создать матрицу такой структуры, по которой Statistica сможет осуществить факторный анализ. Необходимо, чтобы матрица, помимо значений корреляций между переменными, включала еще 4 строки под ними: 1) средние значения рангов, 2) стандартные отклонения рангов, 3) кол-во оцениваемых объектов и 4) тип матрицы. Нажимаем Анализ и выбираем Основные статистики и таблицы
Создание матрицы для расчета ФА Теперь нужно создать матрицу такой структуры, по которой Statistica сможет осуществить факторный анализ. Необходимо, чтобы матрица, помимо значений корреляций между переменными, включала еще 4 строки под ними: 1) средние значения рангов, 2) стандартные отклонения рангов, 3) кол-во оцениваемых объектов и 4) тип матрицы. Нажимаем Анализ и выбираем Основные статистики и таблицы


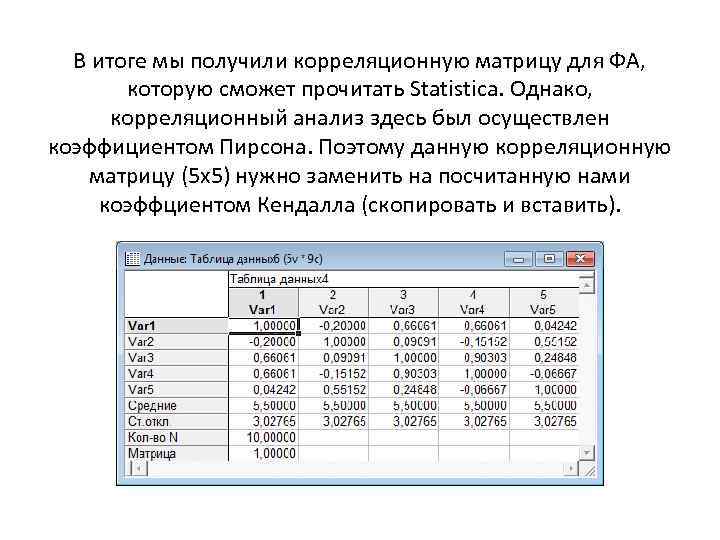 В итоге мы получили корреляционную матрицу для ФА, которую сможет прочитать Statistica. Однако, корреляционный анализ здесь был осуществлен коэффициентом Пирсона. Поэтому данную корреляционную матрицу (5 х5) нужно заменить на посчитанную нами коэффциентом Кендалла (скопировать и вставить).
В итоге мы получили корреляционную матрицу для ФА, которую сможет прочитать Statistica. Однако, корреляционный анализ здесь был осуществлен коэффициентом Пирсона. Поэтому данную корреляционную матрицу (5 х5) нужно заменить на посчитанную нами коэффциентом Кендалла (скопировать и вставить). Как видно, значения корреляций по Кендаллу отличаются от значений по Пирсону. Это объясняется тем, что наши ранги представляют собой шкалы порядка, для которых применение коэффициента Пирсона неадекватно. Теперь можем приступать к факторному анализу.
Как видно, значения корреляций по Кендаллу отличаются от значений по Пирсону. Это объясняется тем, что наши ранги представляют собой шкалы порядка, для которых применение коэффициента Пирсона неадекватно. Теперь можем приступать к факторному анализу.
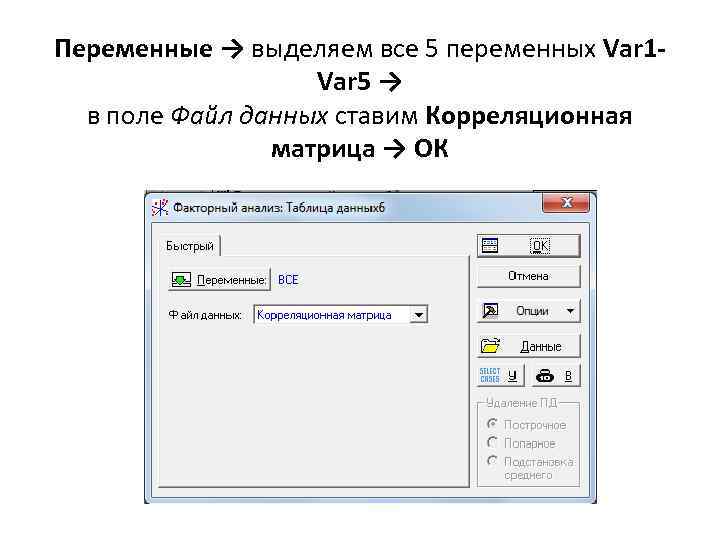 Переменные → выделяем все 5 переменных Var 1 Var 5 → в поле Файл данных ставим Корреляционная матрица → ОК
Переменные → выделяем все 5 переменных Var 1 Var 5 → в поле Файл данных ставим Корреляционная матрица → ОК Макс. Число факторов задаем 5 (т. к. у нас всего 5 переменных) → выбираем Центроидный метод (был разработан Терстоуном и реализует геометрический подход к ФА) → ОК
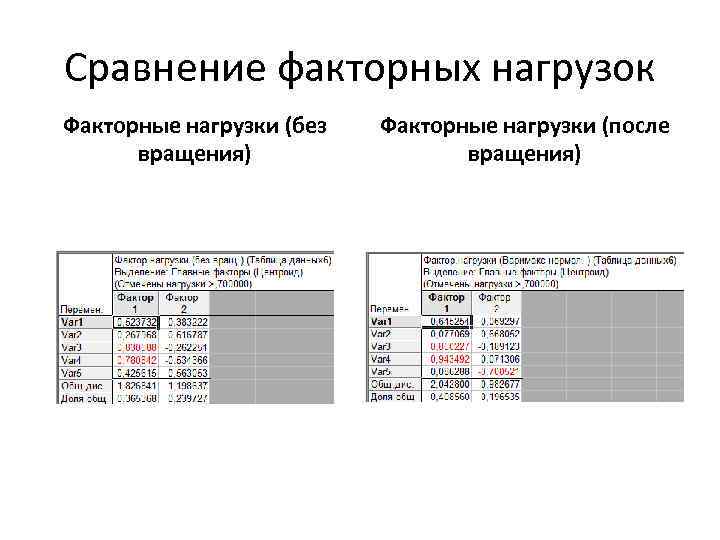
Макс. Число факторов задаем 5 (т. к. у нас всего 5 переменных) → выбираем Центроидный метод (был разработан Терстоуном и реализует геометрический подход к ФА) → ОК Программа выделила 2 фактора. Чтобы посмотреть факторные нагрузки, нажимаем кнопку Факторные нагрузки. Чтобы построить факторную диаграмму, нажмем 2 М график нагрузок.
Программа выделила 2 фактора. Чтобы посмотреть факторные нагрузки, нажимаем кнопку Факторные нагрузки. Чтобы построить факторную диаграмму, нажмем 2 М график нагрузок.

 Statgraphics Centurion q. Факторный анализ q. Выделение факторных нагрузок q. Построение факторной диаграммы q. Построение объектной диаграммы
Statgraphics Centurion q. Факторный анализ q. Выделение факторных нагрузок q. Построение факторной диаграммы q. Построение объектной диаграммы В программе не предусмотрена возможность заложить свою корреляционную матрицу, поэтому начинаем сразу с анализа наших рангов. Вбиваем наши ранги и выбираем Analyze → Variable Data → Multivariate Methods → Factor Analysis
В программе не предусмотрена возможность заложить свою корреляционную матрицу, поэтому начинаем сразу с анализа наших рангов. Вбиваем наши ранги и выбираем Analyze → Variable Data → Multivariate Methods → Factor Analysis
 В итоге, программа выделила нам 2 фактора с уровнем объясненной дисперсии 82, 468 %. Это значит, что этими факторами объясняется 82, 468 % (почти 4/5) всей нашей информации по пяти переменным.
В итоге, программа выделила нам 2 фактора с уровнем объясненной дисперсии 82, 468 %. Это значит, что этими факторами объясняется 82, 468 % (почти 4/5) всей нашей информации по пяти переменным. График каменистой осыпи (2 фактора) На графике показано, что вся объясненная информация приходится на 1 и 2 факторы (2 точки над красной линией)
График каменистой осыпи (2 фактора) На графике показано, что вся объясненная информация приходится на 1 и 2 факторы (2 точки над красной линией) Факторные нагрузки Нажимаем Tables (вторая кнопка слева на панели) Ставим галочку возле Extraction Statistics → ОК
Факторные нагрузки Нажимаем Tables (вторая кнопка слева на панели) Ставим галочку возле Extraction Statistics → ОК Как видно факторные нагрузки на уровне десятых отличаются от тех, что мы получили при ручном расчете и в Statistica. Объясняется это тем, что в Statgraphics нельзя заложить свою корреляционную матрицу и программа всегда считает коэффициентом Пирсона, что не адекватно для данных в шкалах порядка.
Как видно факторные нагрузки на уровне десятых отличаются от тех, что мы получили при ручном расчете и в Statistica. Объясняется это тем, что в Statgraphics нельзя заложить свою корреляционную матрицу и программа всегда считает коэффициентом Пирсона, что не адекватно для данных в шкалах порядка.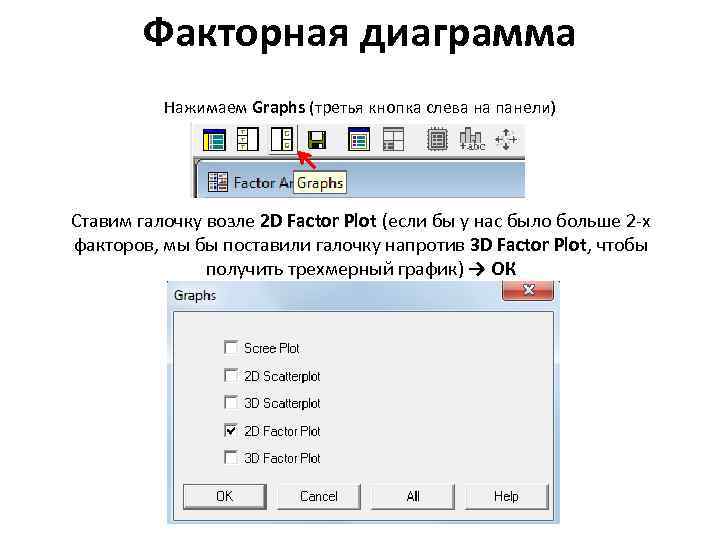 Факторная диаграмма Нажимаем Graphs (третья кнопка слева на панели) Ставим галочку возле 2 D Factor Plot (если бы у нас было больше 2 -х факторов, мы бы поставили галочку напротив 3 D Factor Plot, чтобы получить трехмерный график) → ОК
Факторная диаграмма Нажимаем Graphs (третья кнопка слева на панели) Ставим галочку возле 2 D Factor Plot (если бы у нас было больше 2 -х факторов, мы бы поставили галочку напротив 3 D Factor Plot, чтобы получить трехмерный график) → ОК Мы получили факторную матрицу после вращения. Отрезки (проекции точек, образованные факторными нагрузками) 2 и 5 расположены близко к оси y (стремятся к 0) и удалены от оси x. Это значит, что координаты этих точек по оси x (которая соответствует первому фактору) представлены низкими значениями (0, 6). Следовательно шкалы 2 и 5 представляют собой 1 фактор. По такому же принципу отрезок 1, говорит о том, что шкалы 1, 3 и 4 представляют собой 2 фактор.
Мы получили факторную матрицу после вращения. Отрезки (проекции точек, образованные факторными нагрузками) 2 и 5 расположены близко к оси y (стремятся к 0) и удалены от оси x. Это значит, что координаты этих точек по оси x (которая соответствует первому фактору) представлены низкими значениями (0, 6). Следовательно шкалы 2 и 5 представляют собой 1 фактор. По такому же принципу отрезок 1, говорит о том, что шкалы 1, 3 и 4 представляют собой 2 фактор.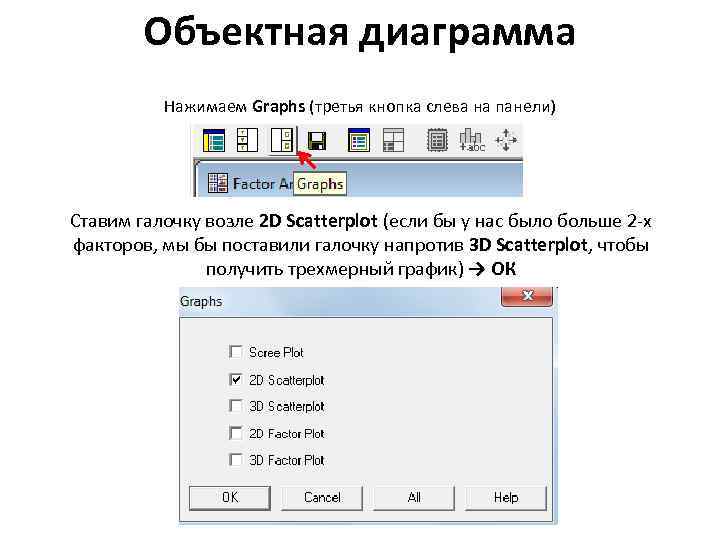 Объектная диаграмма Нажимаем Graphs (третья кнопка слева на панели) Ставим галочку возле 2 D Scatterplot (если бы у нас было больше 2 -х факторов, мы бы поставили галочку напротив 3 D Scatterplot, чтобы получить трехмерный график) → ОК
Объектная диаграмма Нажимаем Graphs (третья кнопка слева на панели) Ставим галочку возле 2 D Scatterplot (если бы у нас было больше 2 -х факторов, мы бы поставили галочку напротив 3 D Scatterplot, чтобы получить трехмерный график) → ОКФакторный анализ - статистический метод, который используется при обработке больших массивов экспериментальных данных. Задачами факторного анализа являются: сокращение числа переменных (редукция данных) и определение структуры взаимосвязей между переменными, т.е. классификация переменных, поэтому факторный анализ используется как метод сокращения данных или как метод структурной классификации.
Важное отличие факторного анализа от всех описанных выше методов заключается в том, что его нельзя применять для обработки первичных, или, как говорят, «сырых», экспериментальных данных, т.е. полученных непосредственно при обследовании испытуемых. Материалом для факторного анализа служат корреляционные связи, а точнее - коэффициенты корреляции Пирсона, которые вычисляются между переменными (т.е. психологическими признаками), включенными в обследование. Иными словами, факторному анализу подвергают корреляционные матрицы, или, как их иначе называют, матрицы интеркорреляций. Наименования столбцов и строк в этих матрицах одинаковы, так как они представляют собой перечень переменных, включенных в анализ. По этой причине матрицы интеркорреляций всегда квадратные, т.е. число строк в них равно числу столбцов, и симметричные, т.е. на симметричных местах относительно главной диагонали стоят одни и те же коэффициенты корреляции.
Главное понятие факторного анализа - фактор. Это искусственный статистический показатель, возникающий в результате специальных преобразований таблицы коэффициентов корреляции между изучаемыми психологическими признаками, или матрицы интеркорреляций. Процедура извлечения факторов из матрицы интеркорреляций называется факторизацией матрицы. В результате факторизации из корреляционной матрицы может быть извлечено разное количество факторов вплоть до числа, равного количеству исходных переменных. Однако факторы, выделяемые в результате факторизации, как правило, неравноценны по своему значению. (5)
С помощью выявленных факторов объясняют взаимозависимость психологических явлений. (7)
Чаще всего в итоге факторного анализа определяется не один, а несколько факторов, по-разному объясняющих матрицу интеркорреляций переменных. В таком случае факторы делят на генеральные, общие и единичные. Генеральными называются факторы, все факторные нагрузки которых значительно отличаются от нуля (нуль нагрузки свидетельствует о том, что данная переменная никак не связана с остальными и не оказывает на них никакого влияния в жизни). Общие - это факторы, у которых часть факторных нагрузок отлична от нуля. Единичные - это факторы, в которых существенно отличается от нуля только одна из нагрузок. (7)
Факторный анализ может быть уместен, если выполняются следующие критерии.
- 1. Нельзя факторизовать качественные данные, полученные по шкале наименований, например, такие, как цвет волос (черный / каштановый / рыжий) и т.п.
- 2. Все переменные должны быть независимыми, а их распределение должно приближаться к нормальному.
- 3. Связи между переменными должны быть приблизительно линейны или, по крайней мере, не иметь явно криволинейного характера.
- 4. В исходной корреляционной матрице должно быть несколько корреляций по модулю выше 0,3. В противном случае достаточно трудно извлечь из матрицы какие-либо факторы.
- 5. Выборка испытуемых должна быть достаточно большой. Рекомендации экспертов варьируют. Наиболее жесткая точка зрения рекомендует не применять факторный анализ, если число испытуемых меньше 100, поскольку стандартные ошибки корреляции в этом случае окажутся слишком велики.
Однако если факторы хорошо определены (например, с нагрузками 0,7, а не 0,3), экспериментатору нужна меньшая выборка, чтобы выделить их. Кроме того, если известно, что полученные данные отличаются высокой надежностью (например, используются валидные тесты), то можно анализировать данные и по меньшему числу испытуемых. (5).
Все явления и процессы хозяйственной деятельности предприятий находятся во взаимосвязи и взаимообусловленности. Одни из них непосредственно связаны между собой, другие косвенно. Отсюда важным методологическим вопросом в экономическом анализе является изучение и измерение влияния факторов на величину исследуемых экономических показателей.
Факторный анализ в учебной литературе трактуется как раздел многомерного статистического анализа, объединяющий методы оценки размерности множества наблюдаемых переменных посредством исследования структуры ковариационных или корреляционных матриц.
Свою историю факторный анализ начинает в психометрике и в настоящее время широко используется не только в психологии, но и в нейрофизиологии, социологии, политологии, в экономике, статистике и других науках. Основные идеи факторного анализа были заложены английским психологом и антропологом Ф. Гальтоном . Разработкой и внедрением факторного анализа в психологии занимались такие ученые как: Ч.Спирмен, Л.Терстоун и Р.Кеттел . Математический факторный анализ разрабатывался Хотеллингом, Харманом, Кайзером, Терстоуном, Такером и другими учеными.
Данный вид анализа позволяет исследователю решить две основные задачи: описать предмет измерения компактно и в то же время всесторонне. С помощью факторного анализа возможно выявление факторов, отвечающих за наличие линейных статистических связей корреляций между наблюдаемыми переменными.
Цели факторного анализа
К примеру, анализируя оценки, полученные по нескольким шкалам, исследователь отмечает, что они сходны между собой и имеют высокий коэффициент корреляции, в этом случае он может предположить, что существует некоторая латентная переменная , с помощью которой можно объяснить наблюдаемое сходство полученных оценок. Такую латентную переменную называют фактором, который влияет на многочисленные показатели других переменных, что приводит к возможности и необходимости отметить его как наиболее общий, более высокого порядка.
Таким образом, можно выделить две цели факторного анализа :
- определение взаимосвязей между переменными, их классификация, т. е. «объективная R-классификация»;
- сокращение числа переменных.
Для выявления наиболее значимых факторов и, как следствие, факторной структуры, наиболее оправданно применять метод главных компонентов . Суть данного метода состоит в замене коррелированных компонентов некоррелированными факторами. Другой важной характеристикой метода является возможность ограничиться наиболее информативными главными компонентами и исключить остальные из анализа, что упрощает интерпретацию результатов. Достоинство данного метода также в том, что он - единственный математически обоснованный метод факторного анализа.
Факторный анализ - методика комплексного и системного изучения и измерения воздействия факторов на величину результативного показателя.
Типы факторного анализа
Существуют следующие типы факторного анализа:
1) Детерминированный (функциональный) - результативный показатель представлен в виде произведения, частного или алгебраической суммы факторов.
2) Стохастический (корреляционный) - связь между результативным и факторными показателями является неполной или вероятностной.
3) Прямой (дедуктивный) - от общего к частному.
4) Обратный (индуктивный) - от частного к общему.
5) Одноступенчатый и многоступенчатый.
6) Статический и динамический.
7) Ретроспективный и перспективный.
Также факторный анализ может быть разведочным - он осуществляется при исследовании скрытой факторной структуры без предположения о числе факторов и их нагрузках и конфирматорным , предназначенным для проверки гипотез о числе факторов и их нагрузках. Практическое выполнение факторного анализа начинается с проверки его условий.
Обязательные условия факторного анализа:
- Все признаки должны быть количественными;
- Число признаков должно быть в два раза больше числа переменных;
- Выборка должна быть однородна;
- Исходные переменные должны быть распределены симметрично;
- Факторный анализ осуществляется по коррелирующим переменным.
При анализе в один фактор объединяются сильно коррелирующие между собой переменные, как следствие происходит перераспределение дисперсии между компонентами и получается максимально простая и наглядная структура факторов. После объединения коррелированность компонент внутри каждого фактора между собой будет выше, чем их коррелированность с компонентами из других факторов. Эта процедура также позволяет выделить латентные переменные, что бывает особенно важно при анализе социальных представлений и ценностей.
Этапы факторного анализа
Как правило, факторный анализ проводится в несколько этапов.
Этапы факторного анализа:
1 этап. Отбор факторов.
2 этап. Классификация и систематизация факторов.
3 этап. Моделирование взаимосвязей между результативным и факторными показателями.
4 этап. Расчет влияния факторов и оценка роли каждого из них в изменении величины результативного показателя.
5 этап. Практическое использование факторной модели (подсчет резервов прироста результативного показателя).
По характеру взаимосвязи между показателями различают методы детерминированного и стохастического факторного анализа
Детерминированный факторный анализ представляет собой методику исследования влияния факторов, связь которых с результативным показателем носит функциональный характер, т. е. когда результативный показатель факторной модели представлен в виде произведения, частного или алгебраической суммы факторов.
Методы детерминированного факторного анализа : Метод цепных подстановок; Метод абсолютных разниц; Метод относительных разниц; Интегральный метод; Метод логарифмирования.
Данный вид факторного анализа наиболее распространен, поскольку, будучи достаточно простым в применении (по сравнению со стохастическим анализом), позволяет осознать логику действия основных факторов развития предприятия, количественно оценить их влияние, понять, какие факторы, и в какой пропорции возможно и целесообразно изменить для повышения эффективности производства.
Стохастический анализ представляет собой методику исследования факторов, связь которых с результативным показателем в отличие от функциональной является неполной, вероятностной (корреляционной). Если при функциональной (полной) зависимости с изменением аргумента всегда происходит соответствующее изменение функции, то при корреляционной связи изменение аргумента может дать несколько значений прироста функции в зависимости от сочетания других факторов, определяющих данный показатель.
Методы стохастического факторного анализа : Способ парной корреляции; Множественный корреляционный анализ; Матричные модели; Математическое программирование; Метод исследования операций; Теория игр.
Необходимо также различать статический и динамический факторный анализ. Первый вид применяется при изучении влияния факторов на результативные показатели на соответствующую дату. Другой вид представляет собой методику исследования причинно-следственных связей в динамике.
И, наконец, факторный анализ может быть ретроспективным, который изучает причины прироста результативных показателей за прошлые периоды, и перспективным, который исследует поведение факторов и результативных показателей в перспективе.
Факторный анализ со статистической точки зрения связан с поиском новых признаков, характеризующих объекты наблюдения на основе имеющейся информации, которая содержится в измеренных значениях k исходных признаков. Всю информацию об п объектах наблюдения можно представить в виде матрицыили прямоугольной таблицы "объект – признак" (табл. 5.6).
Таблица 5.6
Таблица "объект (i) – признак (/)"
Для дальнейшего анализа удобнее использовать матрицу наблюдаемых стандартизованных признаков, которые тоже относятся к категории измеримых, как рассчитанных непосредственно по результатам произведенных наблюдений
Стандартизация производится в соответствии с заменой (5.3), но обычно неизвестные математические ожидания и дисперсии n"j заменяются их выборочными аналогами: выборочной средней
и несмещенной оценкой дисперсии
либо асимптотически несмещенной оценкой дисперсии
Средние значения стандартизованных переменных равны нулю (), а дисперсии – единице ().
Связь новых переменных с наблюдаемыми признаками в факторном анализе аналогична регрессионной, но с тем существенным отличием, что эти новые объясняющие переменные, или факторы, неизвестны и нуждаются в идентификации. В моделях факторного анализа используются общие и индивидуальные факторы. Общие факторы связаны значимыми коэффициентами более чем с одной измеримой переменной. Каждый из индивидуальных факторов v. связан только с однойу-й измеримой переменной. При этом обычно предполагается, что индивидуальные факторы некоррелированы между собой и с общими факторами. Кроме того, для удобства факторы выбираются как стандартизованные:
Второй индекс переменныхобозначает номер объекта наблюдения i - 1,2,..., п. Первый индекс j = 1,2,...,k характеризует номер исходного признака Zjj и соответствующего ему индивидуального эффекта vjY, а для g lt первый индекс / = 1,2,..., от обозначает номер общего фактора.
Коэффициенты при общих факторах можно свести в матрицу
а коэффициенты при индивидуальных факторах для дальнейшего матричного представления модели будут диагональными элементами в диагональной матрице
Включающая нагрузки всех факторов общая матрица коэффициентов, или матрица факторного отображения, будет представлять собой результат объединения элементов обеих матриц:

Матрица значений общих факторов представляет собой матрицу размерности т х п, где т < k:
Матрица значений индивидуальных факторов имеет размерность kxn:
Общая матрица значений факторов может быть образована как результат объединения матриц общих и индивидуальных факторов:
С учетом введенных обозначений модель факторного анализа в матричной форме может быть представлена в виде
Модель факторного анализа с учетом неполного содержания исходной информации об объектах исследования в новой системе координат меньшей размерности (m < k) неизбежно будет содержать помимо общности в виде информации об объектах в системе координат общих факторов и специфичность, представляемую в виде значений характерных факторов. В то же время с учетом случайности выборки и погрешности измерения нормированное наблюдаемое значение содержит истинное значение, индивидуальную особенность Indjj каждого объекта и ошибку измерения е":
В рамках статистического подхода под истинным значением понимается математическое ожидание признака, вторая и третья составляющие характеризуют отклонение отдельного показателя на данном объекте от среднего. Если первая составляющая является общей статистической характеристикой совокупности объектов исследования, то вторая и третья компоненты являются носителями особенностей, присущих данному объекту и методу измерения. В процессе управления важнейшим моментом являются знание и умение учитывать индивидуальные черты отдельных объектов исследования.
Характеристика вариативности – дисперсия – для нормированного значения наблюдаемого признака может быть представлена в следующем виде:
 (5.14)
(5.14)Ошибка измерения обычно оказывается значительно меньше вариативной компоненты, поэтому их часто объединяют . Однако поскольку вариативная составляющая и ошибки измерения возникают независимо друг от друга, то их рассматривают как некоррелированные.
Рассмотрим слагаемые, содержащие сомножитель, величина которого является дисперсией произвольного общего факторапосле нормировки:
Величина дисперсии нормированного общего фактора равна единице:
Рассмотрим в формуле (5.14) слагаемые, содержащие сомножитель . Это коэффициент корреляции между двумя общими факторами, т.е.
После введения обозначения для коэффициента корреляции общих и индивидуальных эффектов
выражение (5.14) можно представить в виде
Из этого представления следует, что
Так как характерный фактор присущ только данной)-й переменной и некоррелирован с общими факторами, тои выражение (5.15) можно упростить:

Дальнейшее упрощение может быть получено для некоррелированных общих факторов, когда и, тогда
В этом случае дисперсия признакаравна сумме относительных вкладов в дисперсию этого признака каждого из т общих и одного характерного фактора.
Компонент общей дисперсииназывается общностью показателя Zj, т.е. суммой относительных вкладов всех т общих факторов в дисперсию признака Zj. Вклад в дисперсию признака z ) характерного фактора Vj, или характерность, определяется слагаемым bj. В свою очередь дисперсия характерного фактора состоит из двух составляющих: связанной со спецификой параметра Sj и связанной с ошибками измерений Е у
Если факторы специфичности Sj и ошибки Ej некоррелированы между собой, то модель факторного анализа примет вид
Вклад характерного фактора в дисперсию признака может быть представлен следующим образом:
Если выделить из дисперсии признака составляющую ошибки, то получим характеристику, называемую надежностью:
Вклад фактора /,. в суммарную дисперсию всех признаков определяется соответствующей суммой квадратов коэффициентов при нормированных значениях:
Вклад всех общих факторов в суммарную дисперсию признаков рассчитывается как сумма вкладов всех факторов:
Отношение этой суммы к размерности исходного признакового пространства
называют полнотой факторизации.
Исходные данные матрицы X (или Z) позволяют получить матрицу парных коэффициентов корреляции R. Для воспроизведения всех связей переменных в корреляционной матрице может быть использована матрица К = (А В):

Введем обозначение для первого слагаемого – редуцированной корреляционной матрицы: /¾ = ЛЛ Т.
Матрицу ВВ" вследствие того, что В является диагональной матрицей, можно представить в виде ВВ Т = В 2.
Таким образом, матрица парных коэффициентов корреляции исходных показателей может быть представлена в виде суммы:
В то время как R является корреляционной матрицей с единицами на главной диагонали, матрица R h представляет собой корреляционную матрицу с общностями на главной диагонали.
Для стандартизованных исходных признаков 7 корреляционная матрица R тождественна ковариационной матрице 2. Если рассматривать данные как выборку из генеральной совокупности, то определенная по выборочным данным матрица 2 (или К) является оценкой истинной ковариационной (корреляционной) матрицы. Несмещенная оценка может быть получена в виде
Рассчитаем редуцированную корреляционную матрицу с учетом равенства (5.4), используя для восстановления нормированных исходных признаков только общие факторы:
Выражение, стоящее между А и А т, является корреляционной матрицей стохастических связей между общими факторами
При этом общее выражение для редуцированной корреляционной матрицы примет вид
Если общие факторы некоррелированы между собой, то матрица С будет единичной, и при этом
Два последних выражения представляют собой фундаментальную теорему факторного анализа.
Пример 5.2
По данным о численности (дг,) и фонде заработной платы (,v2) пяти строительных организаций проведем факторный анализ методом главных компонент. Дано:
Решение
Рассчитаем выборочные характеристики переменных т, и Выборочный коэффициент корреляции равен

Преобразуем матрицу X в матрицу нормированных значений Z с элементами , где
Матрица парных коэффициентов корреляции имеет вид
Для определения собственных значений матрицы R рассмотрим характеристическое уравнение
Отсюда следует, что
Так как по условию компонентного анализа, то, где,
– соответственно дисперсии и вклад первой и второй главных компонент в суммарную дисперсию, равную
Относительный вклад компонент в суммарную дисперсию равен Таким образом,
Определим матрицу собственных векторов из уравнения Собственный векторнаходим из условия
Подставляя полученные значения, получим
откудаили
Нормированный собственный вектор, соответствующий, равен
Собственный вектор V 2 найдем, решив уравнение
откуда.или
Нормированный собственный вектор, соответствующий Х2. равен
тогда нормированная матрица собственных векторов имеет вид

Матрицу факторных нагрузок найдем по формуле
 . Подставив полученные значения, получим
. Подставив полученные значения, получимМатрицу факторных нагрузок используют для интерпретации главных компонент, так как элементы матрицы а }Х) = характеризуют тесноту связи между Хгм признаком и /0-й главной компонентой. В нашем примере первая главная компонента тесно связана с показателями.г, и.г2, а /, характеризует размер предприятия.
Матрицу значений главных компонент F можно получить по формуле
Предварительно найдем обратную матрицу. Так как то
Тогда

Как уже отмечалось, матрица F. которую мы получили, характеризует пять строительных организаций в пространстве главных компонент. Ее можно использовать в задачах классификации и регрессионного анализа. Например, классификация организации но первой главной компоненте /, характеризующей размер предприятий, позволяет ранжировать их в порядке возрастания следующим образом: 4; 1:2: 5: 3. Значения главных компонент определены с точностью до знака, поэтому они могли бы оказаться противоположными для всех объектов, и проведенная ранжировка характеризовала бы размеры предприятий в порядке уменьшения. Определить правильность выбранного знака можно по значениям исходных показателей для крайних проранжированных объектов.
Пример 5.3
На основе информации о значениях семи исходных признаков получены два общих некоррелированных фактора. По известной матрице весовых коэффициентов двух общих факторов Л требуется воспроизвести редуцированную корреляционную матрицу R h, определить редуцированную корреляционную матрицу для случая использования только первого общего фактора R 1 и только второго общего фактора R" при условии, что дисперсия первого общего фактора больше, чем дисперсия второго.
Решение
1. Получим матрицу R h.
Произведем умножение матрицы А на А т и получим редуцированную корреляционную матрицу /?л. т.е. восстановленную из модели факторного анализа при условии, что факторы некоррелированы:

В матрице R /t на главной диагонали стоят дисперсии, представляющие общности, суммарный вклад в переменные имеющихся двух общих факторов.
2. Получим матрицу R 1.
Зададимся вопросом: что было бы, если бы мы пренебрегли вторым общим фактором и провели интерпретацию на основании только первого общего фактора? Какая редуцированная корреляционная матрица R 1 была бы воспроизведена?

Воспроизведенная, или редуцированная, по первому общему фактору матрица восстанавливает связи, объясняемые первым собственным вектором матрицы А. В матрице Д"на главной диагонали стоят вклады в дисперсию первого столбца фактора соответствующих переменных. Они совпадают с вкладами признаков в дисперсию первого фактора aj t.
Как первая, так и вторая воспроизведенные матрицы не отражают всей информации процесса. При этом вторая матрица R" отражает меньше информации, чем первая R 1. Это объясняется тем, что R 1 воспроизводит связи, соответствующие дисперсии первого фактора, которая больше дисперсии второго фактора. Однако и более полная матрица R/, не производит связей, определяемых характерными факторами, так как она объединяет весовые коэффициенты только общих факторов. Необъясненная же часть информации матрицами R/, и А приходится на характерные факторы.
При использовании факторного анализа исследователь сталкивается с различными проблемами. Наиболее часто они возникают в процессе содержательной интерпретации результатов анализа. Многие из проблем носят частный характер, не относящийся непосредственно к факторному анализу и присущий определенному классу задач, например наличие плохо обусловленных матриц парных коэффициентов корреляций, присущее классу экономико-статистических задач.
Среди проблем проведения факторного анализа можно выделить проблемы робастности, общности, выбора факторов, вращения факторов и оценки их значений и содержательной интерпретации, а также проблему построения динамических моделей.
В классическом факторном анализе на основе исходной таблицы "объект – признак" (см. табл. 5.6) формируется матрица нормированных значений исходных признаков. Опыт решения практических задач показывает, что наличие грубых ошибок данных при многомерном анализе может привести к дальнейшим трудностям. Малую чувствительность к наличию грубых ошибок данных обеспечивают робастные оценки параметров: среднего значения и дисперсии или среднего квадратического отклонения.
Рассчитываемая матрица парных коэффициентов корреляции является симметрической матрицей порядка к. Она является диагональной, и на се главной диагонали стоят единицы, соответствующие дисперсиям исходных нормированных показателей. Данная матрица R является исходной для проведения компонентного анализа. Для факторного анализа необходимо получить редуцированную матрицу /?/,.
Редуцированная корреляционная матрица /¾ служит основной для факторного анализа. Она также является симметрической порядка k, но на ее главной диагонали вместо единиц стоят общности hj. На основе этой матрицы рассчитывается матрица весовых коэффициентов Л. Ее элементы являются характеристиками стохастической связи между исходными признаками и общими факторами.
При переходе от редуцированной корреляционной матрицы к матрице весовых коэффициентов необходимо решить проблему нахождения факторов, включающую вопросы определения числа извлекаемых общих факторов и их вида. Значения весовых коэффициентов являются координатами признаков на новых осях координат. Этими координатными осями являются общие факторы. Чаще всего для их нахождения используется метод главных компонент.
Задача воспроизведения матрицы /?>, по матрице А не имеет однозначного решения. Выбор одной из возможных матриц является составной частью решения задачи вращения координатных осей.
После получения новой интегральной системы измерения – общих факторов – можно оценить значения индивидуальных факторов для каждого объекта исследования.
Сопоставление факторных решений в течение длительного периода обеспечивается динамическим моделированием, позволяющим выявить те признаки, влияние которых в будущем будет снижаться или, наоборот, возрастать.
Входит ли больничный в расчет среднего заработка?
Андрюха каменев. Каменев андрей. После того, как вы перестали быть юристом, началась эпоха фотографии
Характеристика с места работы: образец
Как закрыть ИП самостоятельно – пошаговая инструкция
Особенности прохождения независимой оценки качества подготовки обучающихся Независимая оценка качества образовательной деятельности организаций